In the previous blog posts, we gave a brief introduction to the ClusterControl Developer Studio and the ClusterControl Domain Specific Language. We covered some useful examples, e.g., how to extract information from the Performance Schema, how to automatically have advisors scale your database clusters and how to create an advisor that keeps an eye on the MongoDB replication lag. ClusterControl Developer Studio is free to use, and included in the community version of ClusterControl. It allows you to write your own scriptlets, advisors and alerts. With just a few lines of code, you can already automate your clusters. All advisors are open source on Github, so anyone can contribute back to the community!
In this blog post, we will make things a little bit more complex than in our previous posts. Today we will be using our MongoDB replication window advisor that has been recently added to the Advisors Github repository. Our advisor will not only check on the length of the replication window, but also calculate the lag of its secondaries and warn us if the node would be in any risk of danger. For extra complexity, we will make this advisor compatible with a MongoDB sharded environment, and take a couple of edge cases into account to prevent false positives.
MongoDB Replication window
The MongoDB replication window advisor complements the MongoDB lag advisor. The lag advisor informs us of the number of seconds a secondary node is behind the primary/master. As the oplog is limited in size, having slave lag imposes the following risks:
- If a node lags too far behind, it may not be able to catch up anymore as the transactions necessary are no longer in the oplog of the primary.
- A lagging secondary node is less favoured in a MongoDB election for a new primary. If all secondaries are lagging behind in replication, you will have a problem and one with the least lag will be made primary.
- Secondaries lagging behind are less favoured by the MongoDB driver when scaling out reads with MongoDB, it also adds a higher workload on the remaining secondaries.
If we would have a secondary node lagging behind a few minutes (or hours), it would be useful to have an advisor that informs us how much time we have left before our next transaction will be dropped from the oplog. The time difference between the first and last entry in the oplog is called the Replication Window. This metric can be created by fetching the first and last items from the oplog, and calculating the difference of their timestamps.
Calculating the MongoDB Replication Window
In the MongoDB shell, there is already a function available that calculates the replication window for you. However this function is built into the command line shell, so any outside connection not using the command line shell will not have this built-in function:
mongo_replica_2:PRIMARY> db.getReplicationInfo()
{
"logSizeMB" : 1894.7306632995605,
"usedMB" : 501.17,
"timeDiff" : 91223,
"timeDiffHours" : 25.34,
"tFirst" : "Wed Oct 12 2016 22:48:59 GMT+0000 (UTC)",
"tLast" : "Fri Oct 14 2016 00:09:22 GMT+0000 (UTC)",
"now" : "Fri Oct 14 2016 12:32:51 GMT+0000 (UTC)"
}As you can see, this function has a rich output of useful information: the size of the oplog and how much of that has been used already. It also displays the time difference of the first and last items in the oplog.
It is easy to replicate this function by retrieving the first and last items from the oplog. Making use of the MongoDB aggregate function in a one single query is tempting, however the oplog does not have any indexes set on any of the fields. Running an aggregate function on a collection without indexes would require a full collection scan, which would become very slow in an oplog that has a couple of million entries.
Instead we are going to send two individual queries: fetch the first record of the oplog in forward and reverse order. As the oplog already is a sorted collection, we can naturally sort on the reverse of the collection cheaply.
mongo_replica_2:PRIMARY> use local
switched to db local
mongo_replica_2:PRIMARY> db.oplog.rs.find().limit(1);
{ "ts" : Timestamp(1476312539, 1), "h" : NumberLong("-3302015507277893447"), "v" : 2, "op" : "n", "ns" : "", "o" : { "msg" : "initiating set" } }
mongo_replica_2:PRIMARY> db.oplog.rs.find().sort({$natural: -1}).limit(1);
{ "ts" : Timestamp(1476403762, 1), "h" : NumberLong("3526317830277016106"), "v" : 2, "op" : "n", "ns" : "ycsb.usertable", "o" : { "_id" : "user5864876345352853020",
…
}The overhead of both queries is very low and will not interfere with the functioning of the oplog.
In the example above, the replication window would be 91223 seconds (the difference of 1476403762 and 1476312539).
Intuitively you may think it only makes sense to do this calculation on the primary node, as this is the source for all write operations. However, MongoDB is a bit smarter than just serving out the oplog to all secondaries. Even though the secondary nodes will copy entries of the oplog from the primary, for joining members it will offload the delta of transactions loading via secondaries if possible. Also secondary nodes may prefer to fetch oplog entries from other secondaries with low latency, rather than fetching them from a primary with high latency. So it would be better to perform this calculation on all nodes in the cluster.
As the replication window will be calculated per node and we like to keep our advisor as readable as possible, and we will abstract the calculation into a function:
function getReplicationWindow(host) {
var replwindow = {};
// Fetch the first and last record from the Oplog and take it's timestamp
var res = host.executeMongoQuery("local", '{find: "oplog.rs", sort: { $natural: 1}, limit: 1}');
replwindow['first'] = res["result"]["cursor"]["firstBatch"][0]["ts"]["$timestamp"]["t"];
res = host.executeMongoQuery("local", '{find: "oplog.rs", sort: { $natural: -1}, limit: 1}');
replwindow['last'] = res["result"]["cursor"]["firstBatch"][0]["ts"]["$timestamp"]["t"];
replwindow['replwindow'] = replwindow['first'] - replwindow['last'];
return replwindow;
}The function returns the timestamp of the first and last items in the oplog and the replication window as well. We will actually need all three in a later phase.
Calculating the MongoDB Replication lag
We covered the calculation of MongoDB replication lag in the previous Developer Studio blog post. You can calculate the lag by simply subtracting the secondary optimeDate (or optime timestamp) from the primary optimeDate. This will give you the replication lag in seconds.
The information necessary for the replication lag will be retrieved from only the primary node, using the replSetGetStatus command. Similarly to the replication window, we will abstract this into a function:
function getReplicationStatus(host, primary_id) {
var node_status = {};
var res = host.executeMongoQuery("admin", "{ replSetGetStatus: 1 }");
// Fetch the optime and uptime per host
for(i = 0; i < res["result"]["members"].size(); i++)
{
tmp = res["result"]["members"][i];
host_id = tmp["name"];
node_status[host_id] = {};
node_status[host_id]["name"] = host_id;
node_status[host_id]["primary"] = primary_id;
node_status[host_id]["setname"] = res["result"]["set"];
node_status[host_id]["uptime"] = tmp["uptime"];
node_status[host_id]["optime"] = tmp["optime"]["ts"]["$timestamp"]["t"];
}
return node_status;
}We keep a little bit more information than necessary here, but you will see why in the next paragraphs.
Calculating the time left per node
Now that we have calculated both the replication window and the replication lag per node, we can calculate the time left per node where it can theoretically still catch up with the primary. So here we subtract the timestamp of the first entry in the oplog (of the primary) from timestamp of the last executed transaction (optime) of the node.
// Calculate the replication window of the primary against the node's last transaction
replwindow_node = replstatus[host]['optime'] - replwindow_primary['first'];But we are not done yet!
Adding another layer of complexity: sharding
In ClusterControl we see everything as a cluster. Whether you would run a single MongoDB server, a replicaSet or a sharded environment with config servers and shard replicaSets: they are all identified and administered as a single cluster. This means our advisor has to cope with both replicaSet and shard logic.
In the example code above, where we calculated the time left per node, our cluster had a single primary. In the case of a sharded cluster, we have to take into account that we have one replicaSet for the config server and one for the each shard. This means we have to store per node it’s primary node and use that one in the calculation.
The corrected line of code would be:
host_id = host.hostName() + ":" + host.port();
primary_id = replstatus_per_node[host_id]['primary'];
...
// Calculate the replication window of the primary against the node's last transaction
replwindow_node = replstatus['optime'] - replwindow_per_node[primary_id]['first'];For readability we also need to include the replicaSet name in the messages we output via our advisor. If we would not do this, it would become quite hard to distinguish hosts, replicaSets and shards on large sharded environments.
msg = "The replication window for node " + host_id + " (" + replstatus["setname"] + ") is long enough.";Take the uptime into account
Another possible impediment with our advisor is that it will start warning us immediately on a freshly deployed cluster:
- The first and last entry in the oplog will be within seconds of each other after initiating the replicaSet.
- Also on a newly created replicaSet, the probability of it being immediately used would be very low, so there is not much use in alerting on a (too) short replication window in this case either.
- At the same time a newly created replicaSet may also receive a huge write workload when a logical backup is restored, shortening all entries in the oplog to a very short timeframe. This especially becomes an issue if after this burst of writes, no more writes happen for a long time, as now the replication window becomes very short but also outdated.
There are three possible solutions for these problems to make our advisor more reliable:
- We parse the first item in the oplog. If it contains the replicaset initiating document we will ignore a too short replication window. This can easily be done alongside parsing the first record in the oplog.
- We also take the uptime into consideration. If the host’s uptime is shorter than our warning threshold, we will ignore a too short replication window.
- If the replication window is too short, but the newest item in the oplog is older than our warning threshold, this should be considered a false positive.
To parse the first item in the oplog we have to add these lines, where we identify it as a new set:
var res = host.executeMongoQuery("local", '{find: "oplog.rs", sort: { $natural: 1}, limit: 1}');
replwindow['first'] = res["result"]["cursor"]["firstBatch"][0]["ts"]["$timestamp"]["t"];
if (res["result"]["cursor"]["firstBatch"][0]["o"]["msg"] == "initiating set") {
replwindow['newset'] = true;
}Then later in the check for our replication window we can verify all three exceptions together:
if(replwindow['newset'] == true) {
msg = "Host " + host_id + " (" + replstatus["setname"] + ") is a new replicaSet. Not enough entries in the oplog to determine the replication window.";
advice.setSeverity(Ok);
advice.setJustification("");
} else if (replstatus["uptime"] < WARNING_REPL_WINDOW) {
msg = "Host " + host_id + " (" + replstatus["setname"] + ") only has an uptime of " + replstatus["uptime"] + " seconds. Too early to determine the replication window.";
advice.setSeverity(Ok);
advice.setJustification("");
}
else if (replwindow['max'] < (CmonDateTime::currentDateTime().toString("%s") - WARNING_REPL_WINDOW)) {
msg = "Latest entry in the oplog for host " + host_id + " (" + replstatus["setname"] + ") is older than " + WARNING_REPL_WINDOW + " seconds. Determining the replication window would be unreliable.";
advice.setSeverity(Ok);
advice.setJustification("");
}After this we can finally warn / advise on the replication window of the node. The output would look similar to this:
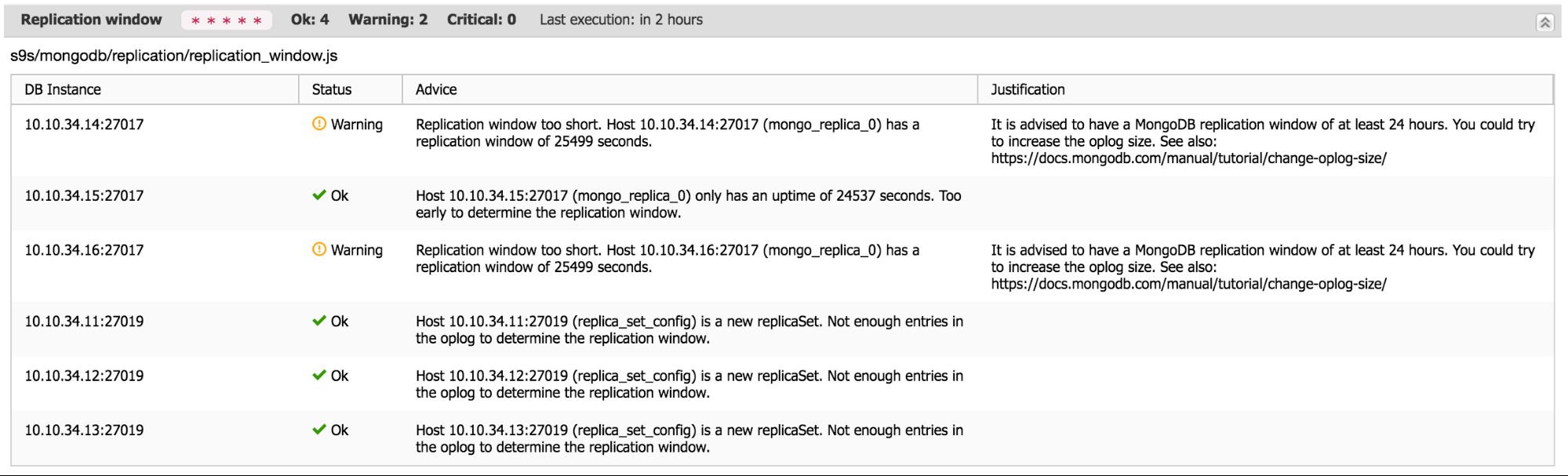
Conclusion
That’s it! We have created an advisor that gathers information from various hosts / replicaSets and combines this to get an exact view of the replication status of the entire cluster. We have also shown how to make things more readable by abstracting code into functions. And the most important aspect is that we have shown how to also think bigger than just the standard replicaSet.
For completeness, here is the full advisor:
#include "common/helpers.js"
#include "cmon/io.h"
#include "cmon/alarms.h"
// It is advised to have a replication window of at least 24 hours, critical is 1 hour
var WARNING_REPL_WINDOW = 24*60*60;
var CRITICAL_REPL_WINDOW = 60*60;
var TITLE="Replication window";
var ADVICE_WARNING="Replication window too short. ";
var ADVICE_CRITICAL="Replication window too short for one hour of downtime / maintenance. ";
var ADVICE_OK="The replication window is long enough.";
var JUSTIFICATION_WARNING="It is advised to have a MongoDB replication window of at least 24 hours. You could try to increase the oplog size. See also: https://docs.mongodb.com/manual/tutorial/change-oplog-size/";
var JUSTIFICATION_CRITICAL=JUSTIFICATION_WARNING;
function main(hostAndPort) {
if (hostAndPort == #N/A)
hostAndPort = "*";
var hosts = cluster::mongoNodes();
var advisorMap = {};
var result= [];
var k = 0;
var advice = new CmonAdvice();
var msg = "";
var replwindow_per_node = {};
var replstatus_per_node = {};
var replwindow = {};
var replstatus = {};
var replwindow_node = 0;
var host_id = "";
for (i = 0; i < hosts.size(); i++)
{
// Find the primary and execute the queries there
host = hosts[i];
host_id = host.hostName() + ":" + host.port();
if (host.role() == "shardsvr" || host.role() == "configsvr") {
// Get the replication window of each nodes in the cluster, and store it for later use
replwindow_per_node[host_id] = getReplicationWindow(host);
// Only retrieve the replication status from the master
res = host.executeMongoQuery("admin", "{isMaster: 1}");
if (res["result"]["ismaster"] == true) {
//Store the result temporary and then merge with the replication status per node
var tmp = getReplicationStatus(host, host_id);
for(o=0; o < tmp.size(); o++) {
replstatus_per_node[tmp[o]['name']] = tmp[o];
}
//replstatus_per_node =
}
}
}
for (i = 0; i < hosts.size(); i++)
{
host = hosts[i];
if (host.role() == "shardsvr" || host.role() == "configsvr") {
msg = ADVICE_OK;
host_id = host.hostName() + ":" + host.port();
primary_id = replstatus_per_node[host_id]['primary'];
replwindow = replwindow_per_node[host_id];
replstatus = replstatus_per_node[host_id];
// Calculate the replication window of the primary against the node's last transaction
replwindow_node = replstatus['optime'] - replwindow_per_node[primary_id]['first'];
// First check uptime. If the node is up less than our replication window it is probably no use warning
if(replwindow['newset'] == true) {
msg = "Host " + host_id + " (" + replstatus["setname"] + ") is a new replicaSet. Not enough entries in the oplog to determine the replication window.";
advice.setSeverity(Ok);
advice.setJustification("");
} else if (replstatus["uptime"] < WARNING_REPL_WINDOW) {
msg = "Host " + host_id + " (" + replstatus["setname"] + ") only has an uptime of " + replstatus["uptime"] + " seconds. Too early to determine the replication window.";
advice.setSeverity(Ok);
advice.setJustification("");
}
else if (replwindow['max'] < (CmonDateTime::currentDateTime().toString("%s") - WARNING_REPL_WINDOW)) {
msg = "Latest entry in the oplog for host " + host_id + " (" + replstatus["setname"] + ") is older than " + WARNING_REPL_WINDOW + " seconds. Determining the replication window would be unreliable.";
advice.setSeverity(Ok);
advice.setJustification("");
}
else {
// Check if any of the hosts is within the oplog window
if(replwindow_node < CRITICAL_REPL_WINDOW) {
advice.setSeverity(Critical);
msg = ADVICE_CRITICAL + "Host " + host_id + " (" + replstatus["setname"] + ") has a replication window of " + replwindow_node + " seconds.";
advice.setJustification(JUSTIFICATION_CRITICAL);
} else {
if(replwindow_node < WARNING_REPL_WINDOW)
{
advice.setSeverity(Warning);
msg = ADVICE_WARNING + "Host " + host_id + " (" + replstatus["setname"] + ") has a replication window of " + replwindow_node + " seconds.";
advice.setJustification(JUSTIFICATION_WARNING);
} else {
msg = "The replication window for node " + host_id + " (" + replstatus["setname"] + ") is long enough.";
advice.setSeverity(Ok);
advice.setJustification("");
}
}
}
advice.setHost(host);
advice.setTitle(TITLE);
advice.setAdvice(msg);
advisorMap[i]= advice;
}
}
return advisorMap;
}
function getReplicationStatus(host, primary_id) {
var node_status = {};
var res = host.executeMongoQuery("admin", "{ replSetGetStatus: 1 }");
// Fetch the optime and uptime per host
for(i = 0; i < res["result"]["members"].size(); i++)
{
tmp = res["result"]["members"][i];
node_status[i] = {};
node_status[i]["name"] = tmp["name"];;
node_status[i]["primary"] = primary_id;
node_status[i]["setname"] = res["result"]["set"];
node_status[i]["uptime"] = tmp["uptime"];
node_status[i]["optime"] = tmp["optime"]["ts"]["$timestamp"]["t"];
}
return node_status;
}
function getReplicationWindow(host) {
var replwindow = {};
replwindow['newset'] = false;
// Fetch the first and last record from the Oplog and take it's timestamp
var res = host.executeMongoQuery("local", '{find: "oplog.rs", sort: { $natural: 1}, limit: 1}');
replwindow['first'] = res["result"]["cursor"]["firstBatch"][0]["ts"]["$timestamp"]["t"];
if (res["result"]["cursor"]["firstBatch"][0]["o"]["msg"] == "initiating set") {
replwindow['newset'] = true;
}
res = host.executeMongoQuery("local", '{find: "oplog.rs", sort: { $natural: -1}, limit: 1}');
replwindow['last'] = res["result"]["cursor"]["firstBatch"][0]["ts"]["$timestamp"]["t"];
replwindow['replwindow'] = replwindow['last'] - replwindow['first'];
return replwindow;
}