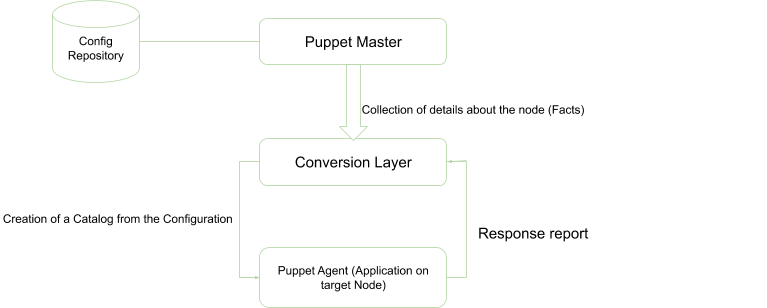
Most software applications nowadays involve some dynamic data storage for extensive future reference in the application itself. We all know data is stored in a database which falls into two categories that are: Relational and Non-relational DBMS.
Your choice of selection from these two will fully depend on your data structure, amount of data involved, database performance and scalability.
Relational DBMS store data in tables in terms of rows such that they use Structured Querying Language (SQL) making them a good choice for applications involving several transactions. They include MySQL, SQLite, and PostgreSQL.
On the other hand, NoSQL DBMS such as MongoDB are document-oriented such that data is stored in collections in terms of documents. This gives a greater storage capacity for a large set of data hence a further advantage in scalability.
In this blog we are assuming you have a better knowledge for either MongoDB or MySQL and hence would like to know the correlation between the two in terms of querying and database structure.
Below is a cheat sheet to further familiarize yourself with the querying of MySQL to MongoDB.
MySQL to MongoDB Cheat Sheet - Terms
| MySQL Terms | MongoDB Terms | Explanation |
|---|---|---|
| Table | Collection | This is the storage container for data that tends to be similar in the contained objects. |
| Row | Document | Defines the single object entity in the table for MySQL and collection in the case of MongoDB. |
| Column | Field | For every stored item, it has properties which are defined by different values and data types. In MongoDB, documents in the same collection, may have different fields from each other. In MySQL, every row must be defined with the same columns from the existing ones. |
| Primary key | Primary key | Every stored object is identified with a unique field value in the case of MongoDB we have _id field set automatically whereas in MySQL you can define your own primary key which is incremental as you create new rows. |
| Table Joins | Embedding and linking documents | Connection associated with an object in a different collection/table to data in another collection/table. |
| where | $match | Selecting data that matches criteria. |
| group | $group | Grouping data according to some criteria. |
| drop | $unset | Removing a column/field from a row/document/ |
| set | $set | Setting the value of an existing column/field to a new value. |
Schema Statements
| MySQL Table Statements | MongoDB Collection Statements | Explanation |
|---|---|---|
The database and tables are created explicitly through the PHP admin panel or defined within a script i.e Creating a Database Creating a table | The database can be created implicitly or explicitly. Implicitly during the first document insert the database and collection are created as well as an automatic _id field being added to this document. You can also create the database explicitly by running this comment in the Mongo Shell | In MySQL, you have to specify the columns in the table you are creating as well as setting some validation rules like in this example the type of data and length that goes to a specific column. In the case of MongoDB, it is not a must to define neither the fields each document should hold nor the validation rules the specified fields should hold. However, in MongoDB for data integrity and consistency you can set the validation rules using the JSON SCHEMA VALIDATOR |
Dropping a table | | This are statements for deleting a table for MySQL and collection in the case of MongoDB. |
Adding a new column called join_date Removing the join_date column if already defined | Adding a new field called join_date This will update all documents in the collection to have the join date as the current date. Removing the join_date field if already defined This will remove the join_date field from all the collection documents. | Altering the structure of the schema by either adding or dropping a column/field. Since the MongoDB architecture does not strictly enforce on the document structure, documents may have fields different from each other. |
Creating an index with the UserId column ascending and Age descending | Creating an index involving the UserId and Age fields. | Indices are generally created to facilitate the querying process. |
| | Inserting new records. |
| | Deleting records from the table/collection whose age is equal to 25. |
| | Deleting all records from the table/collection. |
| | Returns all records from the users table/collection with all columns/fields. |
| | Returns all records from the users table/collection with Age, Gender and primary key columns/fields. |
| | Returns all records from the users table/collection with Age and Gender columns/fields. The primary key is omitted. |
| | Returns all records from the users table/collection whose Gender value is set to M. |
| | Returns all records from the users table/collection with only the Gender value but whose Age value is equal to 25. |
| | Returns all records from the users table/collection whose Gender value is set to F and Age is 25. |
| | Returns all records from the users table/collection whose Age value is not equal to 25. |
| | Returns all records from the users table/collection whose Gender value is set to F or Age is 25. |
| | Returns all records from the users table/collection whose Age value is greater than 25. |
| | Returns all records from the users table/collection whose Age value is less than or equal to 25. |
| | Returns all records from the users table/collection whose Name value happens to have He letters. |
| | Returns all records from the users table/collection whose Gender value is set to F and sorts this result in the ascending order of the id column in case of MySQL and time inserted in the case of MongoDB. |
| | Returns all records from the users table/collection whose Gender value is set to F and sorts this result in the descending order of the id column in case of MySQL and time inserted in the case of MongoDB. |
| or | Counts all records in the users table/collection. |
| or | Counts all records in the users table/collection who happen to have a value for the Name property. |
| or | Returns the first record in the users table/collection. |
| | Returns the first record in the users table/collection that happens to have Gender value equal to F. |
| | Returns the five records in the users table/collection after skipping the first five records. |
| | This sets the age of all records in the users table/collection who have the age greater than 25 to 26. |
| | This increases the age of all records in the users table/collection by 1. |
| | This decrements the age of the first record in the users table/collection by 1. |
To manage MySQL and/or MongoDB centrally and from a single point, visit: https://severalnines.com/product/clustercontrol.